
在AI算力赛道,继基于Blackwell架构GPU多次展现颠覆性潜力后,新一代 GB300 NVL72 平台创造新纪录,NVIDIA正式官宣,其Blackwell Ultra驱动的AI GPU在全部MLPerf训练基准测试中斩获全项第一,不仅印证了该机架级系统对密集型AI工作负载的绝对适配性,更将与竞争对手的性能差距拉至新高度。

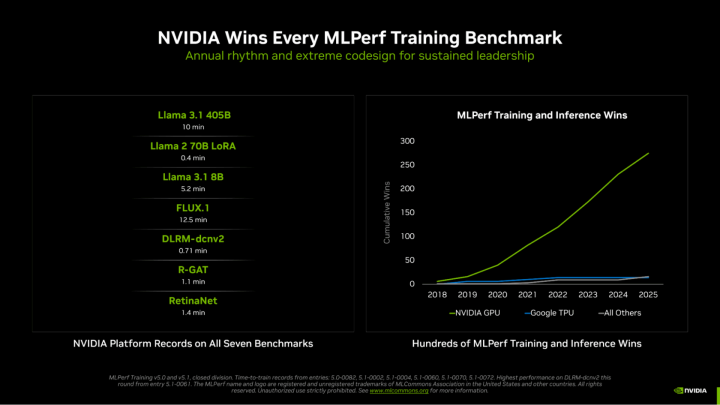
作为唯一一家在所有MLPerf测试项目中完整提交结果的厂商,NVIDIA的统治力贯穿 2025 年至今,GB200与GB300平台已累计斩获 “数百次” MLPerf训练及推理测试胜利,近期核心基准测试成绩尤为震撼,刷新多项行业纪录:
Llama 3.1 405B 参数预训练:仅需 10 分钟
Llama 2 70B LoRA 微调:0.4 分钟(极速完成模型优化)
Llama 3.1 8B 参数预训练:5.2 分钟
FLUX.1 模型训练:12.5 分钟
DLRM-dcnv2 训练:0.71 分钟
R-GAT 训练:1.1 分钟
视网膜网训练:1.4 分钟
性能碾压:数倍超越前代与竞品
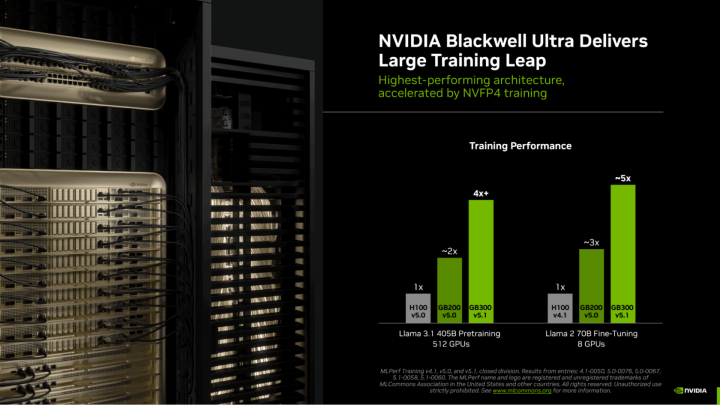
在相同GPU数量的机架系统配置下,Blackwell Ultra GPU的性能表现呈现压倒性优势:
Llama 3.1 40B预训练场景中,GB300性能达到H100的4倍以上,同时较Blackwell GB200 提升近2倍,Llama 2 70B微调任务中,仅需8块GB300 GPU,性能便达到H5的100倍,大幅降低高负载AI任务的硬件门槛与时间成本。
NVIDIA实现LLM训练全层级FP4精度支持,计算速度较传统FP8提升1倍,Blackwell Ultra 架构进一步将这优势放大至3倍,成为“不增GPU数量却实现性能飞跃”的核心密钥,让大模型训练效率实现指数级提升。
GB300 NVL72单GPU搭载279GB HBM3e高速内存,GPU与CPU协同实现40TB超大总内存容量,为超大规模模型训练提供充足带宽支撑;配合800GB/s传输速率的Quantum-X800 InfiniBand网络,实现机架级系统内数据零延迟流转,彻底打破数据传输瓶颈。
NVIDIA表示,它已确保在每一层都采用FP4精度进行LLM训练,与FP8相比,计算速度提高了一倍。Blackwell Ultra进一步将其提高到3倍,与6月份提交的相比,新结果是使用 5,120个Blackwell GPU实现的,训练Llama 3.1 405B参数仅用了 10 分钟。
(文中图片来源于网络)



